개발 DB를 AWS에서 로컬 환경으로 이전하기
안녕하세요 렌딧 데브옵스 팀의 Lucas입니다. 렌딧에서 근무한 지 이제 6개월, 개발 및 인프라 환경에 익숙해진 요즘 천천히 빠르게 변화를 시도하고 있습니다.
그 중 데이터베이스의 로컬 환경으로의 이전 작업에 대해 이야기하려 합니다.
루카스Lucas (LENDIT Devops팀)
렌딧에서 사용하는 AWS 클라우드와 데이터센터를 운영 및 관리하고 있습니다. 훌륭한 개발자들과 함께 렌딧의 정교하고 안정적인 서비스 제공을 위해 고민하고 있습니다.
WHAT
데이터베이스를 AWS에서 로컬 환경으로 이전
WHY
- 하나, 개인정보 처리 작업 변경의 필요
기존에 사용하던 개발용 데이터베이스에서 개인정보의 세세한 부분까지 마스킹 처리할 필요가 있어 추가적인 작업이 필요했습니다. 기존 복제 환경에 각 개인정보 처리 작업을 추가하는 방법 보다는 작업된 데이터베이스를 복제하는 구조가 필요하다고 판단됐습니다. - 둘, 비용의 절감
개발 환경 세트가 최초 3개에서 5개까지 빠르게 증가, 2019년에는 9개까지 증가했습니다. 렌딧은 EC2를 medium, RDS를 small로 사용해 이를 10개 기준으로 계산했을 때 인스턴스 비용이 월 600달러로 책정됩니다. 따라서 매달 600달러를 지출하는 것보다 로컬환경에 장비를 구매해 구축하면 비용을 절감할 수 있습니다. - 셋, 로컬 개발환경
렌딧이 사용하는 AWS는 도쿄리전을 사용하고 있어서 로컬 IDE에서 데이터베이스만 연결해 디버그를 하는 등 로컬 환경에서의 테스트에 시간이 지연된다는 문제가 있었습니다. 데이터베이스를 직접 붙여 테스트하는데 많은 불편함을 겪어 개발환경 개선이 필요하다 생각됐습니다.처음엔 도쿄리전에서 서울리전으로의 변경을 고민했지만 서울리전 역시 동일 비용이 발생하므로 비용까지 커버 가능한 로컬 환경으로 개발을 시도하게 됐습니다. 마침 사내에 머신러닝 용도의 서버가 있고 기존의 렌딧 인프라 대부분이 AWS만을 사용해 이번 기회가 서버 활용에 좋은 때라 생각했습니다. > 기존 개발 환경은? [EC2 환경과 aurora-echo를 통해 개발 데이터베이스 동기화](https://lenditkr.github.io/infrastructure/test-server/)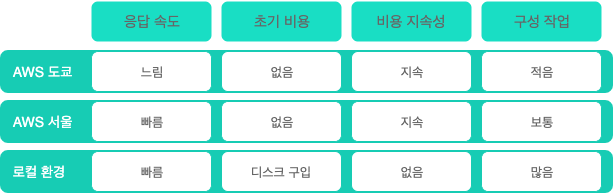 - 환경 비교표 -
- 환경 비교표 -
HOW
신규 테스트 환경에 대한 궁금증
새로운 개발 환경 구성을 위해 무엇을 고려해야할까?
멀티 포트와 도메인
개발환경에서 각자의 닉네임을 활용해 도메인을 바라보는 형태가 돼야 코드 설정파일이 알아보기 쉽고 환경변수를 통해 같은 설정파일로 개발환경이 다르게 적용될 수 있어 ‘도메인 > 아이피 > DB’ 형태의 구성이 돼야 했습니다.1# 환경변수 적용 예시2url: jdbc:mysql://db-dev-${nickname:all}.lendit-dev.domain/dbname한대의 서버를 사용하게 될 경우 하나의 머신에서 다수의 mysql과 접속 IP를 만들어야 하므로 일반적인 방법으로는 요구조건을 만족시킬 수 없었습니다.
복구 작업 시간
테스트 데이터 크기는 30GB를 기준으로 데이터베이스 복구에 한 시간이 걸린다고 가정했을 때, 10명의 개발자가 있다면 전체 작업은 약 5시간이 걸릴 수 있지만 매일 동기화가 필요하기 때문에 복구 작업 시간에 대한 해결이 꼭 필요했습니다.
따라서 sql 파일을 여러번 복구하는 방식으로는 구현이 어렵다 판단돼 최초 1회 복구 이후 데이터 폴더를 복사하는 방법 외에 시간 단축에 대해 고민해야 했습니다.
30GB의 sql파일을 pv를 통해 복구 시간을 측정한 결과로 예측하면 복구 작업에 1시간 정도 소요되게 됩니다.1# pv test-dump-data.sql | mysql -u root -h127.0.0.1 -P12312 test_database;22.32GiB 0:05:16 [8.96MiB/s] [====> ] 10% ETA 0:49:21결국 두 개 조건을 고려하면 한 대의 서버에서 데이터베이스 저장 공간을 나누고 다수의 mysql 서비스를 돌리는 방법을 찾아야 했습니다.
Multi 환경 구성은 무엇으로 해야 할까?
Docker-Compose
처음엔 Docker로 테스트를 했습니다. 관리를 위해서는 Docker-compose를 쓰는 게 편하다 생각돼 아래와 같은 설정 파일로 테스트를 거쳤구요. 간단한 설정이지만 요구조건을 만족할 수 있었습니다.1version: '2'2services:3mysql1:4image: mysql:5.65volumes:6- ./varlib/mysql1:/var/lib/mysql7environment:8MYSQL_ROOT_PASSWORD: password9ports:10- "0.0.0.0:3307:3306"11mysql2:12image: mysql:5.613volumes:14- ./varlib/mysql2:/var/lib/mysql15environment:16MYSQL_ROOT_PASSWORD: password17ports:18- "0.0.0.0:3308:3306"19...각 컨테이너 별 포트를 할당할 수 있는 부분과 로컬 디스크 공간을 탑재해 사용하는 것 모두 만족스러웠는데, 데이터베이스 복구 속도가 너무 느리다는 문제가 있었습니다.
당시 로컬 환경에서 복구 시 1시간이 걸렸다면 컨테이너를 통해 복구했을 시 두 배의 시간이 더 걸렸습니다. 이런 속도로는 한 번의 복구에 더 많은 시간이 걸리므로 개선을 위해 드라이버를 바꾸면서 테스트를 해보는 게 어떤가 판단됐는데요. 그러나 이후에도 가상화 환경의 속도 문제 등이 발생할 것 같아 다른 방법을 찾기로 했습니다.mysqld_multi
그렇게 찾은 방법이 바로 mysqld_multi입니다. 가상화 환경을 사용하지 않고도 mysql_multi를 통해 다수의 mysql을 동작시킬 수 있고 가상 환경이 들어가지 않기에 더 빠른 DB복구 시간을 기대할 수 있었습니다.
신규 환경을 구축하자
신규 환경 구성
위에서 이야기한 멀티 포트, 도메인, 로컬 복사 속도를 구성도로 표현하면 아래와 같습니다.각 도메인이 한 대의 서버에서 다른 IP, 포트 그리고 mysql 데이터에 매핑 되어야 하기에 뒷 부분은 mysqld_multi로 구현하고 앞쪽은 secondary ip와 iptables의 nat 테이블을 통해 구현했습니다. 가장 위에 있는 아이피인 mysqld_multi 0은 처음에 airflow에서 복제된 데이터베이스를 타깃으로 mysqldump를 수행하게 되고 프로세스를 종료시켜서 복사 가능한 상태로 유지됩니다. 이때 생성된 data-0 폴더를 각 폴더로 복사해서 각자의 개발 DM을 생성합니다. 그리고 /var/lib/mysql-ssd/에는 이번 작업을 위해 구매한 2TB SSD가 장착돼 있습니다. 해당 내용을 이야기하기에 앞서 개인정보 처리에 대해 정리하고 설명을 이어 가도록 하겠습니다.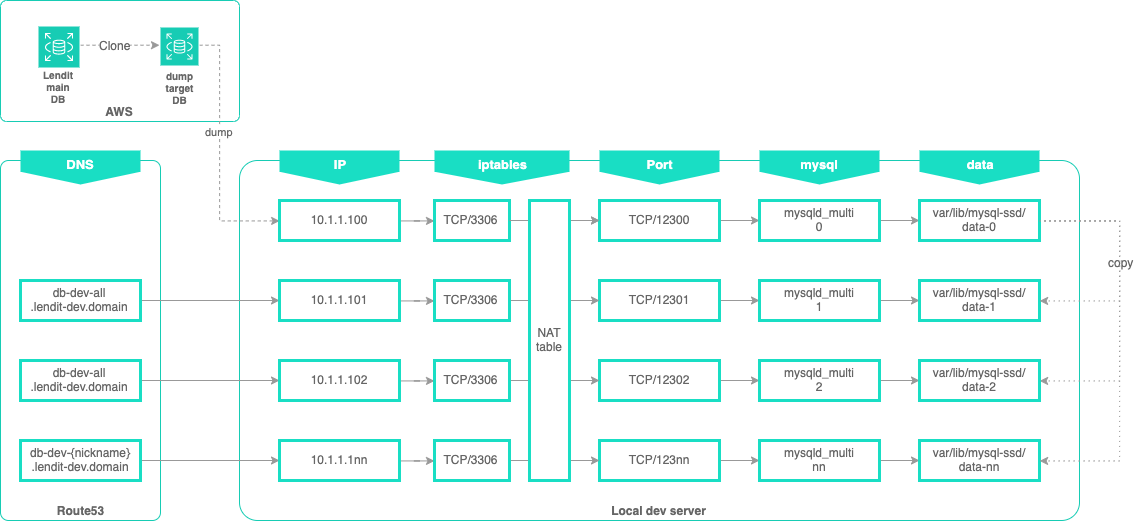
DB복제와 개인정보 처리
해당 작업은 airflow airflow를 통해 작업을 처리하고 있습니다. 데이터베이스 복제 기능을 이용해서 새벽 시간에 데이터베이스를 복제하고 개인정보를 제거하는 작업을 Airflow DAG를 통해서 작업하고 있습니다.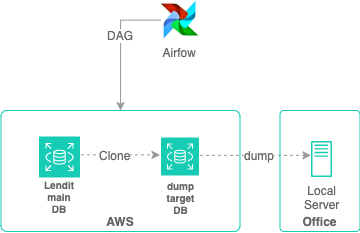
완벽한 전날의 데이터
기존에는 새벽에 aurora-echo 복제 방식을 사용해 crontab을 통해 실행했으나 전날의 데이터베이스 데이터 시간 기준이 더 명확해질 필요가 있어 지정된 시간 복원 기능으로 전날의 23:59:59 시간의 데이터를 타깃하기로 했습니다. 이렇게 더 완벽한 전날의 데이터를 위해 아래 코드를 구현해 사용하고 있습니다.1# 23:59:592datetime_now = datetime.datetime.now()3restore_time = datetime.datetime(year=datetime_now.year, month=datetime_now.month,4day=datetime_now.day, tzinfo=pendulum.timezone('Asia/Seoul')) - datetime.timedelta(5microseconds=1)6# 복제7rds = boto3.client("rds")8rds.clone_cluster(server_name, target_rds, rds_security_groups, restore_time)mysqld_multi 설정
설정 파일은 아래 형태로 관련 데이터 파일 저장 위치를 지정하기만 하면 됩니다.1# my.cnf2[mysqld_multi]3mysqld = /usr/bin/mysqld_safe4mysqladmin = /usr/bin/mysqladmin56[mysqld]7character-set-server = utf88max_connections = 50009user = mysql10bind-address = 0.0.0.01112[mysqld0]13pid-file = /var/lib/mysql-ssd/etc/mysqld0.pid14socket = /var/lib/mysql-ssd/etc/mysqld0.sock15port = 1230016datadir = /var/lib/mysql-ssd/data-01718[mysqld1]19pid-file = /var/lib/mysql-ssd/etc/mysqld1.pid20socket = /var/lib/mysql-ssd/etc/mysqld1.sock21port = 1230122datadir = /var/lib/mysql-ssd/data-123...기존에 레드햇 계열 운영체제에 익숙하다 보니 mysqld_multi 관련 설정 중에 어려움을 겪기도 했는데요. selinux처럼 ubuntu에는 apparmor가 있었습니다. 비활성화 시켜도 되겠지만 아래처럼 mysql 대상만 비활성화 해두고 apparmor가 켜져 있더라도 문제가 없도록 설정해 두는 것이 좋습니다.
관련 내용은 우분투 공식 문서에서 찾아보실 수 있습니다.1sudo ln -s /etc/apparmor.d/local/usr.sbin.mysqld /etc/apparmor.d/disable/apparmor와 폴더 권한 문제 등의 작은 것들을 해결 하다보면 아래와 같이 정상적으로 동작하는 것을 보게 됩니다.
1# netstat -tnlp | grep mysqld2tcp 0 0 0.0.0.0:12301 0.0.0.0:* LISTEN 22325/mysqld3tcp 0 0 0.0.0.0:12302 0.0.0.0:* LISTEN 22562/mysqld4tcp 0 0 0.0.0.0:12303 0.0.0.0:* LISTEN 22797/mysqld5tcp 0 0 0.0.0.0:12304 0.0.0.0:* LISTEN 23037/mysqld6...7# ps -ef | grep mysql8root 4666 1 0 Sep04 ? 00:00:00 /bin/sh /usr/bin/mysqld_safe --pid-file=/var/lib/mysql-ssd/etc/mysqld6.pid --socket=/var/lib/mysql-ssd/etc/mysqld6.sock --port=12306 --datadir=/var/lib/mysql-ssd/data-69mysql 4833 4666 0 Sep04 ? 00:28:34 /usr/sbin/mysqld --basedir=/usr --datadir=/var/lib/mysql-ssd/data-6 --plugin-dir=/usr/lib/mysql/plugin --user=mysql --log-error=/var/lib/mysql-ssd/data-6/lendit-P10S-WS.err --pid-file=/var/lib/mysql-ssd/etc/mysqld6.pid --socket=/var/lib/mysql-ssd/etc/mysqld6.sock --port=1230610root 4904 1 0 Sep04 ? 00:00:00 /bin/sh /usr/bin/mysqld_safe --pid-file=/var/lib/mysql-ssd/etc/mysqld7.pid --socket=/var/lib/mysql-ssd/etc/mysqld7.sock --port=12307 --datadir=/var/lib/mysql-ssd/data-711mysql 5071 4904 0 Sep04 ? 00:26:05 /usr/sbin/mysqld --basedir=/usr --datadir=/var/lib/mysql-ssd/data-7 --plugin-dir=/usr/lib/mysql/plugin --user=mysql --log-error=/var/lib/mysql-ssd/data-7/lendit-P10S-WS.err --pid-file=/var/lib/mysql-ssd/etc/mysqld7.pid --socket=/var/lib/mysql-ssd/etc/mysqld7.sock --port=1230712root 8797 1 0 Sep04 ? 00:00:00 /bin/sh /usr/bin/mysqld_safe --pid-file=/var/lib/mysql-ssd/etc/mysqld12.pid --socket=/var/lib/mysql-ssd/etc/mysqld12.sock --port=12312 --datadir=/var/lib/mysql-ssd/data-1213mysql 8964 8797 0 Sep04 ? 00:24:46 /usr/sbin/mysqld --basedir=/usr --datadir=/var/lib/mysql-ssd/data-12 --plugin-dir=/usr/lib/mysql/plugin --user=mysql --log-error=/var/lib/mysql-ssd/data-12/lendit-P10S-WS.err --pid-file=/var/lib/mysql-ssd/etc/mysqld12.pid --socket=/var/lib/mysql-ssd/etc/mysqld12.sock --port=1231214....IP와 Port 매핑
앞서 이야기한 구조로 IP를 포트로 매핑하기 위해서는 서버에 secondary IP를 추가해 두고 아래와 같은 iptables 명령어로 처리했습니다.1# iptables -t nat -S2...3-A PREROUTING -d 10.1.1.102/32 -p tcp -m tcp --dport 3306 -j DNAT --to-destination 10.1.1.100:123024-A PREROUTING -d 10.1.1.103/32 -p tcp -m tcp --dport 3306 -j DNAT --to-destination 10.1.1.100:123035-A PREROUTING -d 10.1.1.104/32 -p tcp -m tcp --dport 3306 -j DNAT --to-destination 10.1.1.100:123046# iptables -t nat -L7Chain PREROUTING (policy ACCEPT)8target prot opt source destination9DNAT tcp -- anywhere 10.1.1.102 tcp dpt:mysql to:10.1.1.100:1230210DNAT tcp -- anywhere 10.1.1.103 tcp dpt:mysql to:10.1.1.100:1230311DNAT tcp -- anywhere 10.1.1.104 tcp dpt:mysql to:10.1.1.100:12304로컬 서버에서 mysqldump
로컬 서버에서 crontab으로 새벽에 mysqldump를 통해 덤프를 받게 됩니다. 앞서 말한 것처럼 mysql-0는 복사할 대상이기 때문에 데이터베이스 복구 이후 바로 프로세스를 종료시키게 됩니다. 이를 아래 형태의 bash shell로 저장소 삭제를 통해 초기화 하고 새로 저장소를 생성한 뒤 데이터베이스를 복구하는 형태로 매번 깨끗하게 정리가 되도록 했습니다.1#wd=working directory2mysqldump --defaults-extra-file=.lendit.conf > $wd/dumpfile.sql3# 프로세스 종료4mysqladmin -h127.0.0.1 -P12300 -uroot shutdown5# 기존 저장소 삭제6rm -rf /var/lib/mysql-ssd/data-07# 저장소 재 생성8mkdir -p /var/lib/mysql-ssd/data-09chown -R mysql:mysql /var/lib/mysql-ssd/data-010chmod -R 755 /var/lib/mysql-ssd/data-011# 데이터베이스 초기화 및 시작12mysql_install_db --user=mysql --datadir=/var/lib/mysql-ssd/data-013mysqld_multi start 014sleep 1015# 복구16mysql -u root -h127.0.0.1 -P12300 -e "create database ###; create user ###;"17mysql -u root -h127.0.0.1 -P12300 db_name < $wd/dumpfile.sql18sleep 1019# 데이터베이스 종료20mysqladmin -h127.0.0.1 -P12300 -uroot shutdown데이터베이스 복사와 동기화 상태
이제 앞서 생성된 mysql-0에서 총 16개의 데이터베이스를 복사 해야하는데 누군가는 오늘 작업한 내용을 유지하길 원할 수도 있으므로 특정 파일에 각 개발자에 대한 동기화 상태 정보를 저장해두고 해당 값의 ON/OFF 상태에 따라 동기화 여부를 결정하게 됩니다.
ON/OFF의 동기화 상태를 보고 전날의 DB를 신규 DB로 교체할지를 판단하게 됩니다.
상태 저장은 DB로 처리할까 고민도 했었지만 파일로 아래처럼 간단하게 처리했습니다.1$ cat /home/devdb/db_dump/dblist21,all,ON32,name1,ON43,name2,OFF54,name3,ON6...해당 파일은 슬랙봇을 통해 명령을 받고, 로컬 서버로 쉘 명령을 보내 처리하게 됩니다.
슬랙봇에서 아래와 이미지와 같은 형태로 명령어를 받아서 처리하고 있습니다.mysql-0가 준비되고 나면 아래 스크립트가 돌면서 각 데이터베이스 파일을 복사하게 됩니다.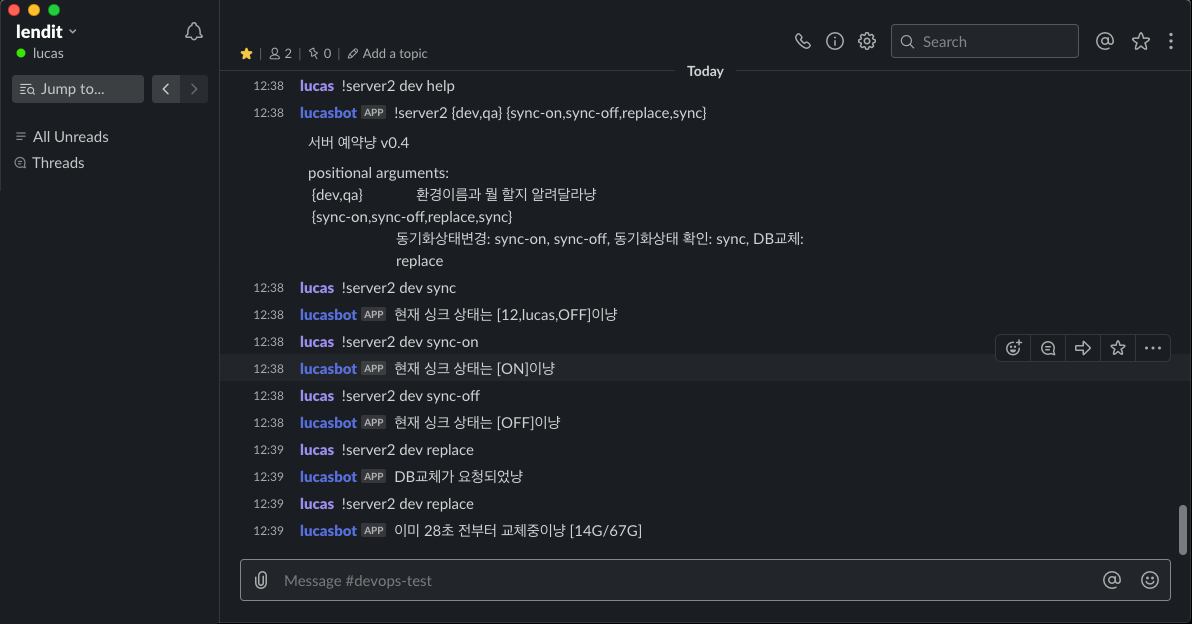
1# 각 데이터베이스 복제 총 16개2for i in {1..16}3do4# 10 미만의 숫자는 두자리 처리5if [ $i -lt 10 ]; then6j="0$i"7else8j="$i"9fi10# 싱크 상태 확인11sync=$(cat $wd/dblist | grep -E "^$i," | cut -d, -f3)12if [ $sync == "ON" ]; then13# 데이터베이스 종료14mysqladmin -h127.0.0.1 -P123$j -uroot shutdown15# 삭제 후 복사16rm -rf /var/lib/mysql-ssd/data-$i17cp -rp /var/lib/mysql-ssd/data-0 /var/lib/mysql-ssd/data-$i18# 데이터 베이스 시작19mysqld_multi start $i20fi21done데이터베이스 복사 속도
이 같은 방식을 사용하면 단순 데이터베이스 복구를 했을때 최초 데이터베이스 복구에는 2시간 정도가 걸리지만 이후에는 나머지 데이터베이스에 대한 복사 작업을 아주 빠르게 끝낼 수 있게 됩니다.1# date; ./cmd_replace.sh lucas ; date2Wed Sep 18 13:48:42 KST 20193lucas = 124Wed Sep 18 13:50:31 KST 2019테스트용 30GB의 데이터베이스에 대해 시간을 측정해봤을 때도 단 3분 만에 전날의 상태로 깨끗하게 복구가 될 수 있습니다. 이렇게 하여 초기 dump 작업을 제외, 15개의 데이터베이스에 30GB의 데이터를 복사하는데 단 1시간만이 소요되게 됩니다.
마치며
기존의 AWS내 개발환경에 사용하는 한달 비용으로 대용량 SSD를 구매해서 이렇게 구성하였고, 이제는 로컬에서 바로 DB를 붙을 수 있게 되었습니다.
그리고 기존의 AWS의 개발 환경은 같은 서버에 CI/CD 형태로 배포만을 계속 하는 형태였는데, 현재는 기존환경에도 변화를 줘서 slack, boto3, airflow 조합을 통해 인프라 자체를 생성하고 삭제하는 형태로 구축하여 사용하고 있습니다.
이 내용까지 한 번에 다뤘으면 좋았을 것 같지만 글이 너무 길어질 것 같아 로컬 DB 환경에 대한 내용만으로 마무리를 해야 될 것 같습니다.
다수의 mysql을 구동시키거나 개발DB환경을 구축 하는 고민을 하는 분들에 조금이나마 도움이 되었으면 좋겠습니다.
감사합니다.